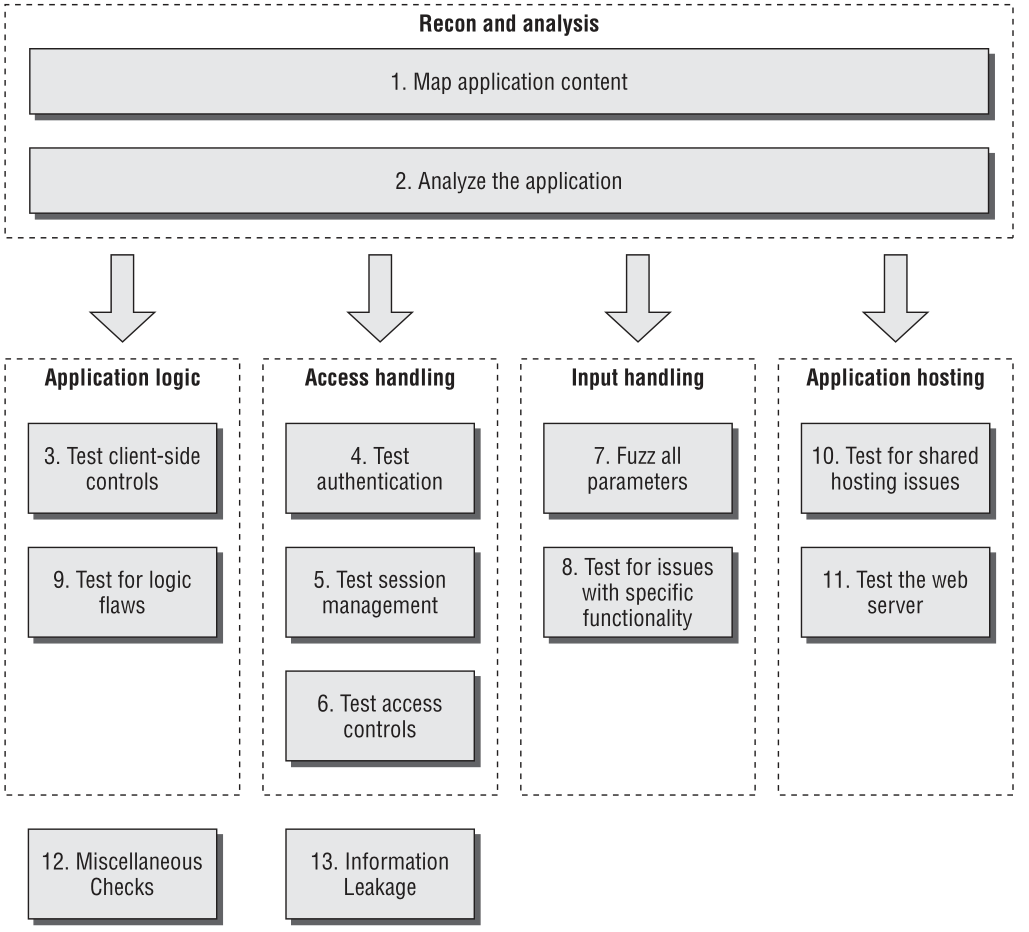
Web黑客方法论框架
Web应用程序黑客的方法论来自书本 The Web Application Hacker’s Handbook
一般步骤如下:
请记住,HTTP请求的不同部分中有几个字符具有特殊的含义。当您在请求中修改数据时,
您应该对这些字符进行url编码,以确保它们按照您希望的方式进行解释.
| ASCII | URL Encode | 用途 |
|---|---|---|
| & | %26 | 分隔URL查询字符串和消息正文中的参数 |
| = | %3d | 分隔URL查询字符串和消息体中的每个参数的名称和值 |
| ? | %3f | 标记URL查询字符串的开头 |
| 空格 | %20 or + |
请求的第一行中标记URL的结束,并可以在cookie头中指示cookie值的结束 |
| + | %2b | |
| ; | %3b | 在Cookie标头中分隔单独的Cookie |
| # | %23 | 在URL中标记片段标识符 |
| % | %25 | 在URL编码方案中用作前缀 |
| null | %00 | |
| 换行 | %0a |
1.映射应用程序的内容(Map the Application’s Content)
| 链接内容 | 其他内容 | 非标准的访问方法 |
|---|---|---|
| 1.1 探索可见的内容 | 1.3 发现隐藏的内容 | 1.5 标识特殊函数 |
| 1.2 查阅公共资源 | 1.4 发现默认的内容 | 1.6 调试参数 |
1.1 探索可见的内容(Explore Visible Content)
1.1.1
使用 Burp 或 ZAP 代理浏览器,然后监控,抓取,分析 web 内容.
1.1.2
用 Burp 或 ZAP监视和分析浏览器正在处理的HTTP和HTML内容。
1.1.3
以正常的方式浏览整个应用程序,访问每个链接和URL,提交每个表单,并通过所有的多步骤功能完成。
尝试在启用和禁用JavaScript以及启用和禁用cookie的情况下进行浏览。
许多应用程序可以处理各种浏览器配置,您可以在应用程序中访问不同的内容和代码路径。
1.1.4
如果应用程序使用身份验证,并且您有或可以创建一个登录帐户,则使用该身份验证访问受保护的功能.
1.1.5
在浏览时,监视通过拦截代理传递的请求和响应,以了解所提交的数据类型以及使用客户机控制服务器端应用程序行为的方式.
1.1.6
Review 被动抓取所生成的site map,并确定您没有使用浏览器浏览过的任何内容或功能。
根据spider的结果,确定每个项的发现位置(例如,在Burp spider中,检查来自详细信息的链接)。
使用浏览器访问每个条目,以便爬行器解析来自服务器的响应以识别任何进一步的内容。
递归地继续这一步,直到没有其他内容或功能被标识出来.
1.1.7
当您完成了手动浏览和被动爬取之后,您可以使用爬取器主动地爬取应用程序,将发现的 URLs 用作种子。
这有时可能会发现您在手动工作时忽略的其他内容。在进行自动爬行之前,首先确定任何危险或可能破坏应用程序会话的URLs,
然后确定爬取器将这些URL从其范围中排除.
1.2 查阅公共资源(Consult Public Resources)
1.2.1
使用Internet搜索引擎和归档(如Wayback Machine)来识别它们为您的目标应用程序索引和存储了什么内容。
1.2.2
使用高级搜索选项来提高你的研究效率.比如,在Google你可以用 site: 去检索目标站点的所有内容;还有 link: 检索链接到它的其他站点.
如果您的搜索标识了应用程序中不再存在的内容,您仍然可能从搜索引擎的缓存中查看这些内容。此旧内容可能包含指向尚未删除的其他资源的链接。
谷歌搜索操作符:完整列表(42个高级操作符)
1.2.3
对在应用程序内容中发现的任何名称和电子邮件地址(如联系信息)进行搜索.包括未在屏幕上呈现的项,如HTML注释。
除了web搜索之外,还要执行news和group搜索.寻找发布到Internet论坛上的有关目标应用程序及其支持基础结构的任何技术细节。
1.2.4
Review任何已发布的WSDL文件,以生成应用程序可能使用的函数名和参数值的列表。
WSDL:指网络服务描述语言 (Web Services Description Language).WSDL是基于 XML 的用于描述 Web Services 以及如何访问 Web Services 的语言.
1.3 发现隐藏内容(Discover Hidden Content)
1.3.1
确认应用程序如何处理不存在项目的请求。对已知的有效和无效资源进行一些手动请求,并比较服务器的响应,以建立一种简单的方法来识别项目是否存在。
1.3.2
获取常用文件和目录名以及常用文件扩展名的清单。将应用程序中实际观察到的所有项以及从中推断出的项添加到这些列表中。
尝试理解应用程序开发人员使用的命名约定。例如,如果有两个页面分别叫做AddDocument.jsp和ViewDocument.jsp也可以是名为EditDocument.jsp和RemoveDocument.jsp的页面。
1.3.3
检查所有客户端代码,以确定关于隐藏服务器端的任何线索内容,包括HTML注释和禁用的表单元素。
1.3.4
使用第14章中描述的自动化技术,根据目录、文件名和扩展列表发出大量请求。监控服务器的响应,确认哪些项是存在的且可访问的。
1.3.5
递归地执行这些内容发现练习,使用新的枚举内容和模式作为进一步的用户定向爬行和进一步的自动发现的基础。
1.4 发现默认内容(Discover Default Content)
1.4.1
在web服务器上运行Nikto来检测任何默认的或已知的内容。使用Nikto的选项,使其效用最大化。例如,可以使用-root选项指定一个目录来检查默认内容,或者使用-404指定一个字符串来标识自定义File Not Found页面。
1.4.2
手动验证任何潜在的有趣发现,以消除结果中的任何误报。
1.4.3
请求服务器的根目录,在Host报头中指定IP地址,并确定应用程序是否使用不同的内容进行响应。如果是,运行一个Nikto扫描的IP地址以及服务器名。
1.4.4
向服务器的根目录发出请求,指定用户User-Agent头的范围,如www.useragentstring.com/pages/useragentstring.php所示。
1.5 枚举标识符指定的函数(Enumerate Identifi er-Specifi ed Functions)
1.5.1
通过在请求参数中传递函数的标识符来标识访问特定应用程序函数的任何实(如:/admin.jsp?action=editUser 或 /main.php?func=A21)
1.5.2
将步骤1.3中使用的内容发现技术应用于用于访问各个函数的机制。例如,如果应用程序使用一个包含函数名的参数,则首先确定在指定无效函数时它的行为,并尝试建立一种简单的方法来识别何时请求了一个有效的函数。编制一份常见函数名的列表,或循环遍历观察到正在使用的标识符的语法范围。将这个练习自动化,以尽可能快且容易地枚举有效的功能。
1.5.3
如果适用,根据功能路径(而不是URL)编译应用程序内容映射,显示所有枚举的函数、逻辑路径以及它们之间的依赖关系.(参见第4章中的示例)
1.6 调试参数测试(Test for Debug Parameters)
1.6.1
选择一个或多个应用程序页面或其中可能实现隐藏的调试参数(如debug=true)函数。这些最可能出现在关键功能中,如login, search, and file upload
or file download。
1.6.2
使用常用调试参数名称(如debug、test、hide和source)和常用值(如true、yes、on和1)的清单。遍历这些函数的所有排列,将每个名name/value 对提交给每个目标函数。对于POST请求,在URL查询字符串和请求体中都提供参数。使用第14章中描述的技术来自动化这个练习。例如,您可以在Burp intruder中使用cluster bomb攻击类型来组合两个有效载荷列表的所有排列。
1.6.3
检查应用程序的响应,看看是否有异常表明添加的参数对应用程序的处理有影响。