参考:The Web Application Hacker’s Handbook (Chapter 2)
web应用程序的基本安全问题——所有用户输入都是不可信的——导致了应用程序使用许多安全机制来防御攻击。实际上,所有的应用程序都采用了概念上类似的机制,尽管设计的细节和实现的效率差别很大。
web应用程序使用的防御机制包括以下核心元素:
- 1.处理用户对应用程序数据和功能的访问,以防止用户获得未经授权的访问
- 2.处理应用程序功能的用户输入,以防止格式错误的输入导致不希望的行为
- 3.处理攻击者,以确保应用程序在被直接攻击时行为正确,并采取适当的防御和攻击措施来挫败攻击者
- 4.通过允许管理员监视应用程序的活动并确认其功能来管理应用程序本身
1.处理用户访问(Handling User Access)
几乎任何应用程序都需要满足的核心安全需求是控制用户对其数据和功能的访问。典型的情况有几个不同类别的用户,例如匿名用户、普通认证用户和管理用户。此外,在许多情况下,允许不同的用户访问不同的数据集。例如,web邮件应用程序的用户应该能够阅读他们自己的电子邮件,而不能阅读其他人的电子邮件。
大多数web应用程序使用三种相互关联的安全机制来处理访问:
- 1.身份验证
- 2.会话管理
- 3.访问控制
1.1 身份验证(Authentication)
当今的大多数web应用程序都采用传统的自动识别模型,即用户提交用户名和密码,然后应用程序对其有效性进行检查。图2-1显示了一个典型的登录函数。在安全关键型应用程序(如在线银行使用的应用程序)中,此基本模型通常由附加凭据和多级登录过程进行补充。当安全性要求更高时,可以使用基于客户端认证、智能卡或质询响应令牌的其他身份验证模式。除了核心的登录过程之外,身份验证机制通常还使用一系列其他支持功能,如自注册、帐户恢复和密码更改功能。
尽管身份验证机制非常简单,但在设计和实现方面都存在广泛的缺陷。常见的问题可能使攻击者能够识别其他用户的用户名、猜测他们的密码或通过利用逻辑中的缺陷绕过登录功能。当您攻击web应用程序时,您应该对它所包含的各种与身份验证相关的功能投入大量的注意力。令人惊讶的是,此功能中的缺陷常常使您能够获得对敏感数据和功能的未授权访问。
1.2 会话管理(Session Management)
处理用户访问过程中的下一个逻辑任务是管理经过身份验证的用户会话。成功登录到应用程序后,用户将访问各种页面和函数,并从浏览器发出一系列HTTP请求。与此同时,应用程序还从不同的用户接收无数其他请求,其中一些请求是经过身份验证的,而另一些则是匿名的。为了实施有效的访问控制,应用程序需要一种方法来识别和处理来自每个唯一用户的一系列请求。
实际上,所有web应用程序都通过为每个用户创建会话并向用户发出标识会话令牌来满足这一要求。会话本身是服务器上保存的一组数据结构,用于跟踪用户与应用程序交互的状态。令牌是应用程序映射到会话的唯一字符串。当用户接收到令牌时,浏览器会在随后的每个HTTP请求中将其自动提交回服务器,从而使应用程序能够将请求与该用户关联起来。HTTP cookie是传输会话令牌的标准方法,尽管许多应用程序为此使用隐藏的表单字段或URL查询字符串。如果用户在一定时间内没有发出请求,则会话在理想情况下已过期,如图2-2所示。
漏洞的主要方面来自于如何生成令牌的缺陷,使攻击者能够猜测向其他用户发出的令牌,以及随后如何处理令牌的缺陷,使攻击者能够捕获其他用户的令牌。
少数应用程序通过跨多个请求使用其他方法重新标识用户,从而免除了对会话令牌的需要。如果使用HTTP内置的身份验证机制,浏览器会自动在每个请求中重新提交用户的凭据,从而使应用程序能够直接从这些请求中识别用户。在其他情况下,应用程序将状态信息存储在客户端而不是服务器上,通常以加密的形式存储,以防止篡改。
1.3 访问控制(Access Control)
处理用户访问过程中的最终逻辑步骤是做出并执行关于每个请求应该被允许还是被拒绝的正确决定。如果刚才描述的机制运行正常,应用程序就知道从哪个用户那里接收到每个请求。在这个基础上,它需要决定用户是否被授权执行他所请求的操作,或者访问他所请求的数据,如图2-3所示。
由于典型访问控制需求的复杂性,这种机制是安全漏洞的常见来源,使攻击者能够获得未经授权的数据和功能访问。开发人员经常对用户将如何与应用程序交互做出错误的假设,并且经常忽略一些应用程序的访问控制检查。探测这些漏洞通常是很费力的,因为本质上对每个功能项都需要重复相同的检查。然而,由于普遍存在访问控制缺陷,因此在攻击web应用程序时,这种努力总是值得的。第8章描述了如何自动化执行严格的访问控制测试所涉及的一些工作。
2.处理用户输入(Handling User Input)
所有用户输入都是不可信的。针对web应用程序的各种攻击都涉及提交意外的输入,这些攻击会导致应用程序设计人员没有预料到的行为。相应地,应用程序安全防御的一个关键要求是应用程序必须以安全的方式处理用户输入。
2.1 各种输入(Varieties of Input)
典型的web应用程序以许多不同的形式处理用户提供的数据。某些类型的输入验证可能不适合所有这些形式的输入。图2-4显示了通常由用户注册函数执行的输入验证类型。

在许多情况下,应用程序可以对一个特定的输入项进行非常严格的有效性检查。例如,提交给登录函数的用户名可能需要最多8个字符,并且只包含字母字符。
在其他情况下,应用程序必须容忍更大范围的可能输入。例如,发送到个人详细信息页面的地址可能包含字母、数字、空格、连字符、撇号和其他字符。但是,对这一项目仍然可以施加限制。数据不应该超过合理的长度限制(比如50个字符),并且不应该包含任何HTML标记。
2.2 输入处理方法(Approaches to Input Handling)
处理用户输入的问题通常采用各种广泛的方法。对于不同的情况和不同类型的输入,不同的方法通常是可取的,并且有时可能需要多种方法的组合。
2.2.1 Reject Known Bad(黑名单)
这种方法通常使用一个黑名单,其中包含一组已知用于攻击的文字字符串或模式。验证机制会阻止任何与黑名单匹配的数据,并允许其他数据。
通常,这被认为是验证用户输入最不有效的方法,主要有两个原因。首先,web应用程序中的一个典型漏洞可以使用各种各样的输入加以利用,这些输入可以以各种方式进行编码或表示。除了在最简单的情况下,黑名单可能会遗漏一些可用于攻击应用程序的输入模式。第二,开发技术在不断发展。利用现有漏洞类别的新方法不太可能被当前的黑名单所阻止。
许多基于黑名单的过滤器可以通过对被阻塞的输入进行细微的调整而几乎令人尴尬地绕过。例如:
- 如果
SELECT被阻塞,则尝试SeLeCt - 如果
or 1=1--被阻塞,则尝试or 2=2-- - 如果
alert('xss')被阻塞,则尝试prompt('xss')
在其他情况下,可以通过在表达式之间使用非标准字符来中断应用程序执行的标记,从而绕过设计来阻止特定关键字的过滤器。例如:
SELECT/*foo*/username,password/*foo*/FROM/*foo*/users
<img%09onerror=alert(1) src=a>
最后,许多基于黑名单的过滤器(尤其是在web应用程序防火墙中实现的过滤器)容易受到空字节攻击。由于在托管和非托管执行上下文中处理字符串的方式不同,所以在阻塞表达式之前插入空字节可能会导致某些筛选器停止处理输入,因此无法识别表达式。例如:
%00<script>alert(1)</script>
第18章描述了攻击web应用程序防火墙的各种其他技术。
利用空字节处理的攻击出现在web应用程序安全的许多领域。在空字节用作字符串分隔符的上下文中,可以使用它来终止对某个后端组件的文件名或查询。在允许和忽略空字节的上下文中(例如,在某些浏览器的HTML中),可以将任意空字节插入被阻塞的表达式中,以击败一些基于黑名单的过滤器.
2.2.2 Accept Known Good(白名单)
这种方法使用一个白名单,其中包含一组文字字符串或模式,或一组已知的只匹配良性输入的标准。验证机制允许匹配白名单的数据并阻塞其他所有数据。例如,在数据库中查找请求的产品代码之前,应用程序可能会验证它只包含字母和数字字符,且长度正好为6个字符。考虑到将对产品代码进行的后续处理,开发人员知道通过此测试的输入不可能导致任何问题。
在这种方法可行的情况下,它被认为是处理潜在恶意输入的最有效方法.
2.2.3 Sanitization(消毒)
这种方法认识到有时需要接受不能保证安全的数据。应用程序不会拒绝该输入,而是以各种方式对其进行消毒,以防止其产生任何负面影响。潜在的恶意字符可以从数据中删除,只留下已知的安全字符,或者在进一步处理之前对它们进行适当的编码或转义。
基于数据清理的方法通常是非常有效的,并且在许多情况下,可以将它们作为恶意输入问题的一般解决方案。 例如,针对跨站点脚本攻击的通常防御措施是在将危险字符嵌入应用程序页面之前对其进行HTML编码(请参阅第12章)。 但是,如果需要在一项输入中容纳几种潜在的恶意数据,则很难实现有效的清理。 在这种情况下,需要一种边界验证方法,如下所述。
2.2.4 Safe Data Handling(安全数据处理)
由于以不安全的方式处理用户提供的数据,因此会出现许多Web应用程序漏洞。 通常,不是通过验证输入本身而是通过确保对输入执行的处理本身是安全的,可以避免漏洞。 在某些情况下,可以使用避免常见问题的安全编程方法。 例如,可以通过正确使用参数化查询进行数据库访问来防止SQL注入攻击(请参见第9章)。 在其他情况下,可以以避免固有的不安全做法(例如将用户输入传递给操作系统命令解释器)的方式设计应用程序功能。
这种方法不能应用于Web应用程序需要执行的每种任务。 但是,只要有可用,它就是处理潜在恶意输入的有效通用方法。
2.2.5 Semantic Checks(语义检查)
到目前为止,所描述的防御措施都满足了针对各种格式错误的数据进行防御的需求,这些数据的内容经过精心设计以干扰应用程序的处理。 但是,由于存在某些漏洞,攻击者提供的输入与普通的非恶意用户可能提交的输入相同。 使它成为恶意软件的原因是提交它的不同情况。 例如,攻击者可能试图通过更改以隐藏形式字段传输的帐号来获取对另一个用户的银行帐户的访问权限。 语法验证的数量不会区分用户的数据和攻击者的数据。 为了防止未经授权的访问,应用程序需要验证所提交的帐号属于已提交的帐号。
2.3 边界验证(Boundary Validation)
服务器端应用程序首次接收用户数据的时间点代表了巨大的信任边界。 此时,应用程序需要采取措施以抵御恶意输入。
当我们开始检查一些实际的漏洞时,就会发现,由于几个原因,这个简单的输入验证图是不充分的:
- 考虑到应用程序实现的功能范围广泛以及所使用的技术不同,典型的应用程序需要防御各种基于输入的攻击,每种攻击都可能使用各种精心制作的数据。 在外部边界设计单一机制来抵御所有这些攻击将非常困难。
- 许多应用程序功能涉及将一系列不同类型的处理链接在一起。 用户提供的单个输入可能会导致不同组件中的许多操作,每个组件的输出都将用作下一个的输入。 随着数据的转换,它可能与原始输入没有任何相似之处。 熟练的攻击者可能能够操纵应用程序,从而在处理的关键阶段生成恶意输入,从而攻击接收此数据的组件。 在外部边界实施验证机制以预见处理每条用户输入的所有可能结果将非常困难。
- 针对不同类型的基于输入的攻击进行防御可能需要对用户输入执行不同的验证检查,这些检查相互之间是不兼容的。例如,防止跨站点脚本攻击可能要求应用程序将
>字符HTML进行编码为>,防止命令注入攻击可能需要应用程序阻塞包含&和;字符。试图在应用程序的外部边界同时阻止所有类型的攻击有时是不可能的。
一个更有效的模型使用边界验证的概念。 在此,服务器端应用程序的每个单独组件或功能单元都将其输入视为来自潜在的恶意源。
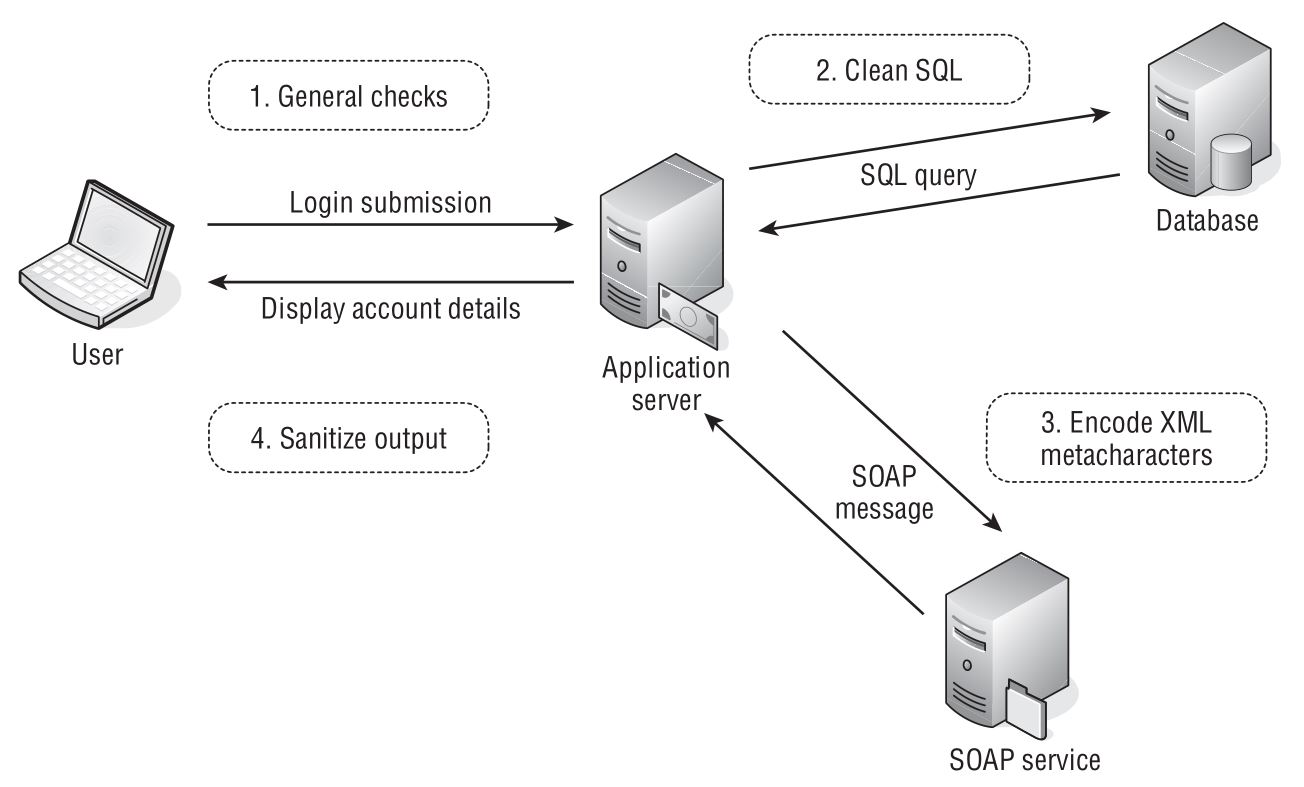
图2-5说明了一种典型的情况,其中边界验证是抵御恶意输入的最有效方法。用户登录将导致对用户提供的输入执行多个处理步骤,并在每个步骤中执行适当的验证:
- 1.该应用程序接收用户的登录详细信息。 表单处理程序验证输入的每一项仅包含允许的字符,在特定的长度限制内,并且不包含任何已知的攻击签名。
- 2.该应用程序执行SQL查询以验证用户的凭据。 为了防止SQL注入攻击,在构造查询之前,应将用户输入内可用于攻击数据库的所有字符转义。
- 3.如果登录成功,则应用程序会将用户个人资料中的某些数据传递给SOAP服务,以检索有关其帐户的更多信息。 为了防止SOAP注入攻击,对用户个人资料数据中的所有XML元字符都进行了适当的编码。
- 4.该应用程序将用户的帐户信息显示回用户的浏览器。 为了防止跨站点脚本攻击,该应用程序会对嵌入在返回的页面中的任何用户提供的数据进行HTML编码。
如果此功能的变体涉及到将数据传递给进一步的应用程序组件,则需要在相关的信任边界处实现类似的防御。例如,如果登录失败导致应用程序向用户发送警告电子邮件,则可能需要检查合并到电子邮件中的任何用户数据,以进行SMTP注入攻击。
2.4 多步骤验证和规范化(Multistep Validation and Canonicalization)
当用户提供的输入作为验证逻辑的一部分跨多个步骤进行操作时,输入处理机制会遇到一个常见的问题。如果不小心处理此过程,攻击者可能会构造成功通过验证机制走私恶意数据的精雕细琢的输入。当应用程序试图通过删除或编码某些字符或表达式来清理用户输入时,就会出现这种问题。例如,应用程序可能试图通过删除表达式来抵御一些跨站点脚本攻击:
<script>
来自任何用户提供的数据。但是,攻击者可以通过提供以下输入来绕过过滤器:
<scr<script>ipt>
删除阻止的表达式后,周围的数据收缩以恢复恶意有效负载,因为没有递归地应用筛选器。
同样,如果对用户输入执行了多个验证步骤,则攻击者可能能够利用这些步骤的顺序来绕过过滤器。 例如,如果应用程序首先递归删除../,然后递归删除..\,则可以使用以下输入来使验证无效:
....\/
出现与数据规范化相关的问题。 从用户的浏览器发送输入时,可以用各种方式对其进行编码。 存在这些编码方案,以便可以通过HTTP安全传输异常字符和二进制数据(有关更多详细信息,请参见第3章)。 规范化是将数据转换或解码为通用字符集的过程。 如果在应用输入过滤器之后执行任何规范化,则攻击者可能能够使用合适的编码方案来绕过验证机制。
例如,应用程序可能通过阻止包含撇号的输入来尝试防御某些SQL注入攻击。 但是,如果随后对输入进行了规范化,则攻击者可能能够使用双URL编码来破坏过滤器。 例如:
%2527
当接收到此输入时,应用程序服务器执行其正常的URL解码,因此输入变为:
%27
它不包含撇号,所以应用程序的参数允许它。但是,当应用程序执行进一步的URL解码时,输入被转换成撇号,从而绕过过滤器。 如果应用程序删除撇号而不是将其括起来,然后执行进一步的规范化,则以下绕过可能有效:
%%2727
值得注意的是,在这些情况下,多个验证和规范化步骤无需全部在应用程序的服务器端进行。 例如,在以下输入中,几个字符已被HTML编码:
<iframe src=javascript:alert(1) >
如果服务器端应用程序使用输入过滤器阻止某些JavaScript表达式和字符,则编码后的输入可能会成功绕过过滤器。 但是,如果随后将输入复制到应用程序的响应中,则某些浏览器将对src参数值进行HTML解码,然后将执行嵌入式JavaScript。
除了旨在用于Web应用程序中的标准编码方案外,在其他情况下(应用程序使用的组件将数据从一个字符集转换为另一个字符集),还会出现规范化问题。 例如,某些技术基于字符的印刷字形中的相似性来执行字符的“最佳匹配”映射。 在这里,字符«和»可以分别转换为<和>,而Ÿ和Â可以转换为Y和A。 通常可以利用此行为来将屏蔽的字符或关键字走私到应用程序的输入过滤器之外。
3.处理攻击者(Handling Attackers)
设计对安全性至关重要的应用程序的任何人都必须假定,它将由专门和熟练的攻击者直接作为目标。 应用程序安全机制的关键功能是能够以受控方式处理这些攻击并对其做出反应。 这些机制通常结合了防御性措施和攻击性措施,旨在尽可能使攻击者感到沮丧,并向应用程序所有者提供适当的通知和已发生情况的证据。 为应对攻击者而采取的措施通常包括以下任务:
- 错误处理
- 维护审计日志
- 提醒管理员
- 对攻击做出反应
3.1 处理错误(Handling Errors)
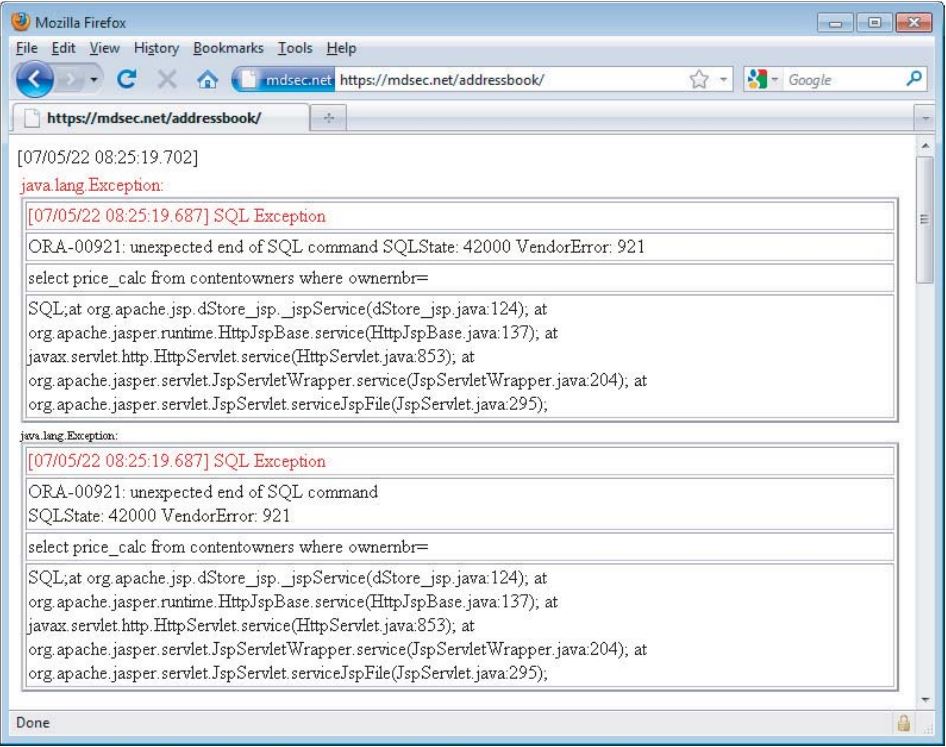
在生产环境中,应用程序不应该在其响应中返回任何系统生成的消息或其他调试信息。正如您将在本书中看到的,过于冗长的错误消息可以极大地帮助恶意用户进一步攻击应用程序。在某些情况下,攻击者可以利用有缺陷的错误处理来在错误消息本身中检索有意义的信息,从而为从应用程序中窃取数据提供了有价值的渠道。图2-6显示了导致详细错误消息的未处理错误的示例。
此外,大多数应用程序服务器都可以通过定制的方式来处理未处理的应用程序错误,例如通过显示一个不提供信息的错误消息。有关这些措施的更多细节见第15章。
3.2 维护审核日志(Maintaining Audit Logs)
审计日志的价值主要体现在对应用程序的入侵尝试进行调查时。此类事件后,有效的审计日志应该启用应用程序所有者了解发生了什么,哪些漏洞(如果有的话)被利用,无论攻击者获得未授权访问数据或执行任何未经授权的行动,尽可能提供证据,入侵者的身份。
在任何安全性很重要的应用程序中,都应该理所当然地记录关键事件。至少,这些通常包括以下内容:
- 与身份验证功能相关的所有事件,如登录成功和失败,以及密码更改
- 关键的交易,如信用卡支付和资金转移
- 被访问控制机制阻止的访问尝试
- 任何包含明显表明恶意意图的已知攻击字符串的请求
任何包含明显表明恶意意图的已知攻击字符串的请求
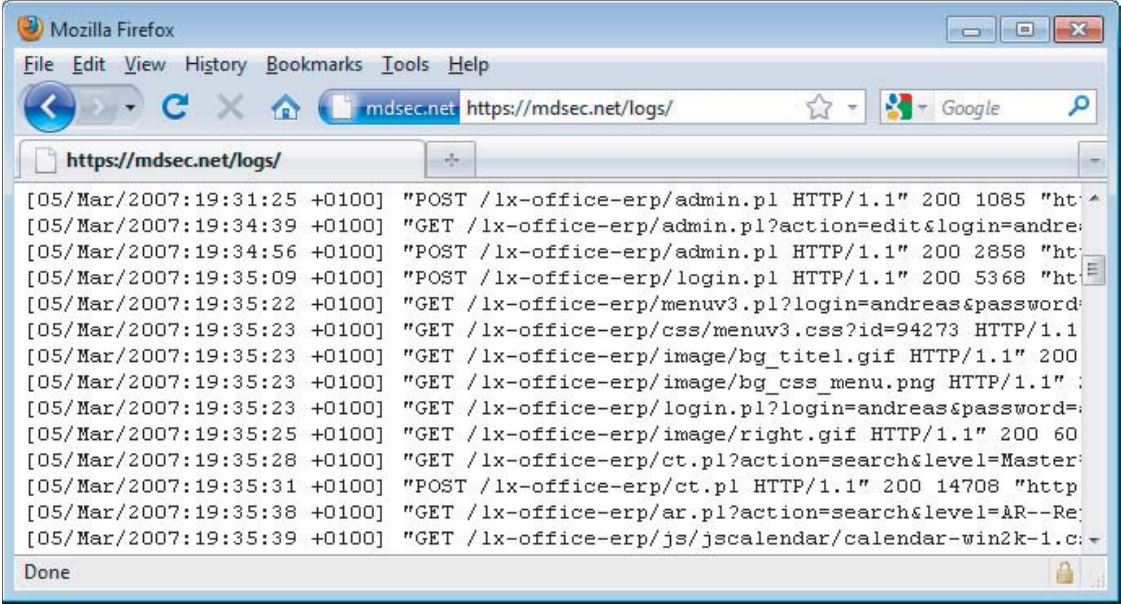
有效的审计日志通常记录每个事件的时间、接收请求的IP地址和用户的帐户(如果经过身份验证)。需要对这些日志进行严格保护,防止未经授权的读或写访问。一种有效的方法是在只接受来自主应用程序的更新消息的自治系统上存储审计日志。在某些情况下,日志可能会被写入一次媒体,以确保在成功攻击时它们的完整性。
就攻击面而言,保护不力的审计日志可以为攻击者提供信息金矿,暴露大量敏感信息,如会话令牌和请求参数。此信息可能使攻击者能够立即危害整个应用程序,如图2-7所示。
3.3 提醒管理员(Alerting Administrators)
审核日志使应用程序的所有者可以追溯调查入侵尝试,并在可能的情况下对肇事者采取法律行动。 但是,在许多情况下,希望对尝试的攻击采取实时的实时措施。 例如,管理员可以阻止攻击者正在使用的IP地址或用户帐户。 在极端情况下,他们甚至可能在调查攻击并采取补救措施时使应用程序脱机。 即使已经发生了成功的入侵,但如果尽早采取防御措施,其实际效果也可能会减弱。
警报机制监视的异常事件通常包括以下内容:
- 使用异常,例如从单个IP地址或用户接收到大量请求,这表明存在脚本攻击
- 业务异常,例如从一个银行账户转入或转出的资金数量异常
- 包含已知攻击字符串的请求
- 对普通用户隐藏的数据进行了修改的请求
3.4 应对攻击(Reacting to Attacks)
除了警告管理员外,许多对安全性至关重要的应用程序还包含内置机制,可对被识别为潜在恶意的用户做出防御性反应。
4.管理应用程序(Managing the Application)
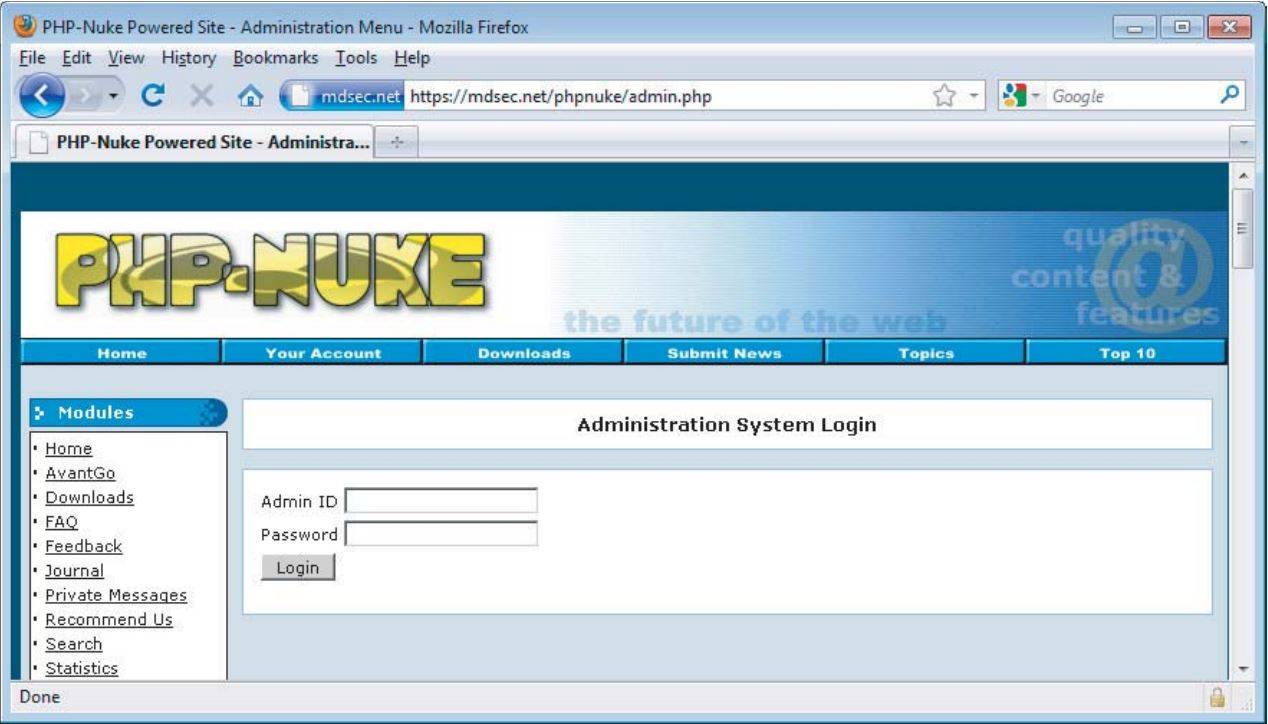
在许多应用程序中,管理功能是在应用程序内部实现的,可以通过与其核心非安全性功能相同的Web界面访问该功能,如图2-8所示。 在这种情况下,管理机制代表了应用程序攻击面的关键部分。 它对攻击者的主要吸引力是作为特权提升的工具。 例如:
- 身份验证机制中的弱点可能使攻击者获得管理访问权,从而有效地损害整个应用程序。
- 许多应用程序没有对它们的一些管理功能实现有效的访问控制。攻击者可能会找到一种创建具有强大权限的新用户帐户的方法。
- 管理功能通常涉及显示来自普通用户的数据。管理界面中的任何跨站点脚本都可能导致用户会话的破坏,而用户会话保证具有强大的特权。
- 管理功能经常受到不太严格的安全测试,因为它的用户被认为是可信的,或者因为渗透测试人员只能访问低权限的帐户。此外,该功能常常需要执行固有的危险操作,包括访问磁盘或操作系统命令上的fi。如果攻击者可以破坏管理功能,他通常可以利用它来控制整个服务器。
5.Summary
尽管存在广泛的差异,但几乎所有web应用程序都以某种形式使用相同的核心安全机制。这些机制代表了应用程序对恶意用户的主要防御,因此也包含了应用程序攻击表面的大部分.
在这些组件中,处理用户访问和用户输入的机制是最重要的,当您将目标定位于应用程序时,应该将大部分注意力放在这些机制上。这些机制中的缺陷通常会导致应用程序的完全破坏,从而使您能够访问属于其他用户的数据、执行未经授权的操作并注入任意代码和命令。
: