参考:The Web Application Hacker’s Handbook Chapter 4 Mapping the Application
攻击应用程序的第一步是收集和检查有关该应用程序的一些关键信息,以更好地了解您所面临的挑战。
映射练习首先枚举应用程序的内容和功能,以了解应用程序的功能以及行为方式。 此功能的大部分易于识别,但其中某些功能可能是隐藏的,需要一定程度的猜测和运气才能发现。
主要任务是仔细检查其行为的各个方面,其核心安全机制以及所采用的技术(在客户端和服务器上)。 这将使您能够识别应用程序暴露的主要攻击面,从而可以确定最有趣的区域,应在这些区域中进行后续探测以发现可利用的漏洞。
随着应用程序变得越来越大,功能越来越多,有效的映射是一项宝贵的技能。 经验丰富的专家可以快速对功能的所有区域进行分类,查找与实例相对应的漏洞类别,同时将大量时间投入到测试其他特定领域,以发现高风险问题。
本章描述了在应用程序映射过程中需要遵循的实际步骤,可以用来最大化其有效性的各种技术和技巧,以及一些可以在此过程中帮助您的工具。
1. Enumerating Content and Functionality(枚举内容和功能)
在典型的应用程序中,大多数内容和功能都可以通过手动浏览来识别。基本的方法是遍历应用程序,从主初始页面开始,跟踪每个链接,并通过导航控制所有多级功能(如用户注册或密码重置)。如果应用程序包含site map,这可以为枚举内容提供一个有用的起点。
然而,要对列举的内容进行严格的检查,并获得所标识的所有内容的完整记录,您必须使用比简单浏览更高级的技术。
1.1 Web Spidering(网络爬虫)
各种工具可以执行自动的网站搜索,这些工具的工作方式是:请求一个web页面,解析它以获得到其他内容的链接,请求这些链接,然后递归地继续操作,直到没有发现新的内容为止.
工具:Burp Suite, WebScarab, Zed Attack, CAT.
许多Web服务器在Web根目录中包含一个名为robots.txt的文件,该文件包含该站点不希望Web蜘蛛访问或搜索引擎建立索引的URL列表。 有时,robots.txt文件可能会对Web应用程序的安全起反作用。
1.1.1.1 自动化网络爬虫限制
- 不寻常的导航机制(比如:使用复杂的JavaScript代码动态创建和处理菜单)通常不会被自动化工具正确地处理,因此它们可能错过应用程序的整个区域.
- 隐藏在已编译的客户端对象(如:Flash或Java applet)中的链接可能不会被爬行器捕获.
- 多阶段功能通常实现细粒度的输入验证检查,这些检查不接受自动化工具可能提交的值。例如,用户注册表单可能包含的名称,电子邮件地址,电话号码和邮政编码的字段。因此它不会越过注册表单,因此不会发现除了注册表单之外的其他任何内容或功能.
- 自动化的爬虫通常使用URL作为唯一内容的标识符.为了避免持续的爬取,它们识别已经被请求的链接内容,且不再请求它.然而,许多应用程序使用基于表单的导航,其中相同的URL可能返回不同的内容和功能.
- 与前一点相反,一些应用程序将易变数据放在URL中,这些URL实际上并不用于识别资源或函数(如:包含计时器或随机数种子的参数).应用程序的每个页面可能包含一组新的URL,爬虫必须请求这些URL,将导致它无限的去爬取.
- 当应用程序使用身份验证时,有效的应用程序爬行器必须能够处理这个问题,以访问身份验证保护的功能。前面提到的爬行器可以通过手动配置爬行器来实现这一点,可以使用经过身份验证的会话的令牌,也可以使用提交到登录函数的凭据来配置爬行器。但是,即使这样做了,通常也会发现spider的操作会由于各种原因中断经过身份验证的会话:
- 通过跟踪所有URL,爬行器将在某个时候请求注销功能,导致其会话中断。
- 如果爬行器将无效的输入提交给敏感函数,则应用程序可以防御性地终止会话。
- 如果应用程序使用每页令牌,则爬虫几乎肯定会通过请求超出其预期顺序的页面而无法正确处理这些令牌,这可能导致整个会话终止。
1.2 User-Directed Spidering(用户控制的爬虫)
这是一种更复杂、更可控的技术,通常比自动蜘蛛更受欢迎。在这里,用户使用标准的浏览器以正常的方式浏览应用程序,试图浏览所有的应用程序功能。当他这样做时,结果的流量通过一个结合了拦截代理和爬行器的工具传递,爬行器监视所有请求和响应。该工具构建应用程序的地图,对浏览器访问的所有url进行分级。它还以与普通应用程序感知爬行器相同的方式解析所有应用程序响应,并使用它发现的内容和功能更新站点地图。Burp套件和WebScarab中的spider可以以这种方式使用(有关更多信息,请参见第20章)。
与自动爬虫相比,用户控制爬虫的好处:
- 当应用程序使用不同寻常或复杂的导航机制时,用户可以使用浏览器以正常的方式跟踪这些机制。用户访问的任何函数和内容都由proxy/spider工具处理。
- 用户控制提交给应用程序的所有数据,并确保满足数据验证需求。
- 用户可以以通常的方式登录到应用程序,并确保经过身份验证的会话在整个映射过程中保持活动。如果执行的任何操作导致会话终止,用户可以再次登录并继续浏览。
- 任何危险的功能,如
deleteUser.jsp,都是完全枚举的,并合并到代理的站点地图中,因为到它的链接将从应用程序的响应中解析出来。但是用户可以自行决定实际请求或执行哪些功能。
HACK STEPS
- 将您的浏览器配置为使用Burp作为本地代理
- 正常浏览整个应用程序,尝试访问您发现的每个
link/URL,提交每个表单,并通过所有多步骤功能完成。尝试在启用和禁用JavaScript以及启用和禁用cookie的情况下进行浏览。许多应用程序可以处理不同的浏览器配置,您可以在应用程序中访问不同的内容和代码路径。 - 检查由proxy/spider工具生成的站点地图,并确定没有手动浏览的任何应用程序内容或功能。建立爬行器如何枚举每个项。例如,在Burp Spider中,检查来自details的链接。使用您的浏览器,手动访问项目,以便proxy/spider工具解析来自服务器的响应,以识别任何进一步的内容。递归地继续这一步,直到没有进一步的内容或功能被识别。
- 可选地,告诉工具使用所有已枚举的内容作为起点来主动地爬行站点。要做到这一点,首先要识别出任何危险的或可能破坏应用程序会话的url,并配置确保爬行器将这些url从其范围中排除。运行爬行器并查看其发现的任何附加内容的结果。
由proxy/spider工具生成的站点地图包含大量关于目标应用程序的信息,这些信息在以后识别应用程序公开的各种攻击面时会很有用。
1.3 Discovering Hidden Content(挖掘隐藏的内容)
应用程序通常包含不直接链接到主可视内容或不能从主可视内容访问的内容和功能。一个常见的例子是为测试或调试目的而实现的功能,并且从未被删除。
发现该功能的攻击者可能会利用它来提高她在应用程序中的特权。
还有无数其他情况,其中可能存在前面描述的映射技术无法识别的有趣内容和功能:
- 实时文件的备份副本。 对于动态页面,其文件扩展名可能已更改为未映射为可执行文件的文件扩展名,使您可以查看页面源中的漏洞,然后可以在实时页面上利用这些漏洞。
- 备份存档包含Web根内部(或实际上位于外部)的文件的完整快照,可能使您能够轻松识别应用程序内的所有内容和功能。
- 已部署到服务器进行测试但尚未与主应用程序链接的新功能。
- 现成的应用程序中的默认应用程序功能已向用户表面隐藏,但仍在服务器上。
- 尚未从服务器中删除的文件的旧版本。 对于动态页面,这些页面可能包含在当前版本中已修复但在旧版本中仍可利用的漏洞。
- 配置并包括包含敏感数据(例如数据库凭据)的文件。
- 配置并包括包含敏感数据(例如数据库凭据)的文件。
- 源代码中的注释在极端情况下可能包含用户名和密码等信息,但更有可能提供有关应用程序状态的信息。 测试此功能或类似内容之类的关键短语是从哪里开始寻找漏洞的有力指标。
- 日志文件可能包含敏感信息,例如有效的用户名,会话令牌,访问的URL和执行的操作。
有效发现隐藏内容需要自动和手动技术的结合,并且通常取决于运气。
1.3.1 暴力破解技术(Brute-Force Techniques)
第14章介绍了如何利用自动化技术来加快对应用程序的任何攻击。 在当前的信息收集环境中,可以使用自动化向Web服务器发出大量请求,以尝试猜测隐藏功能的名称或标识符。
自动识别隐藏内容的第一步可能包括以下请求,以定位其他目录:
http://eis/About/
http://eis/abstract/
http://eis/academics/
http://eis/accessibility/
http://eis/accounts/
http://eis/action/
...
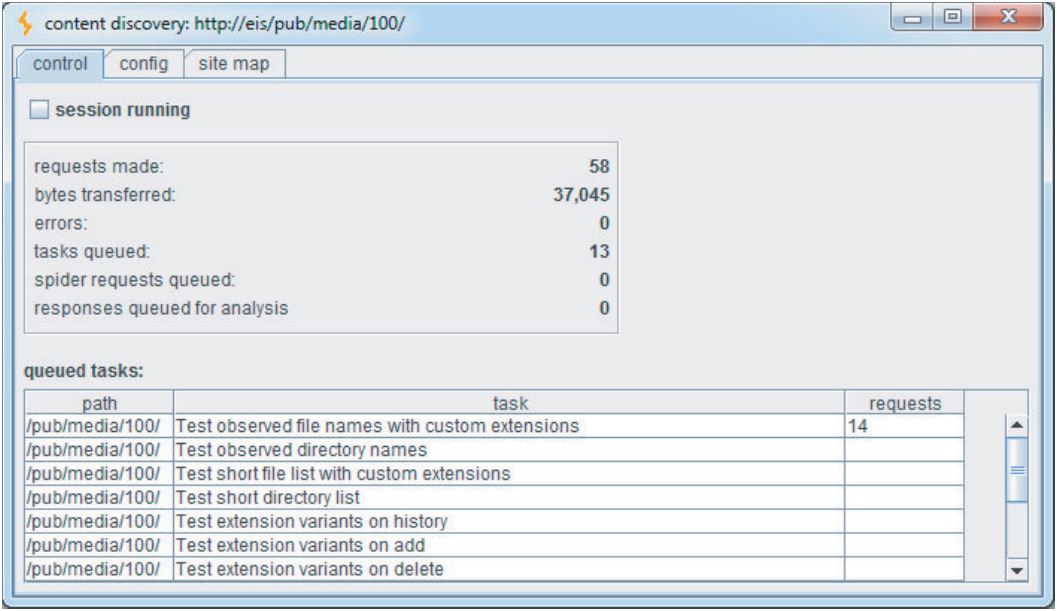
Burp Intruder可用于遍历常见目录名称列表并捕获服务器响应的详细信息,可对其进行查看以识别有效目录。 图4-4显示了Burp Intruder被配置为探测位于Web根目录的公用目录。
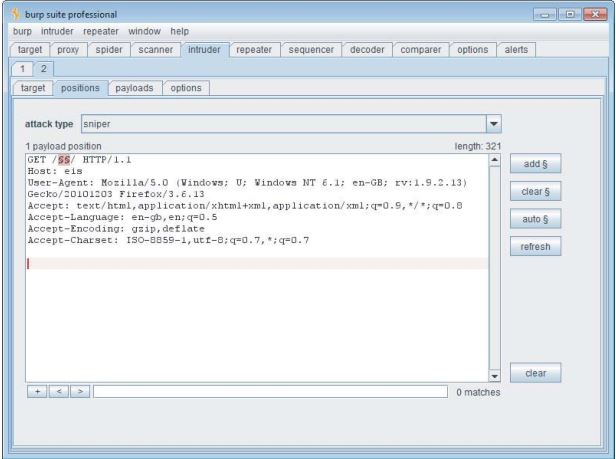 图4-4
图4-4
执行攻击后,单击status和length之类的列标题会相应地对结果进行排序,使您能够快速识别潜在的其他资源列表,如图4-5所示。 对目录和子目录进行暴力破解后,您可能希望在应用程序中查找其他页面。 特别令人感兴趣的是/auth目录,其中包含在爬网过程中标识的登录资源,对于未经身份验证的攻击者来说,这很可能是一个很好的起点。 同样,您可以在此目录中请求一系列文件:
http://eis/auth/About/
http://eis/auth/Aboutus/
http://eis/auth/AddUser/
http://eis/auth/Admin/
http://eis/auth/Administration/
http://eis/auth/Admins/
...
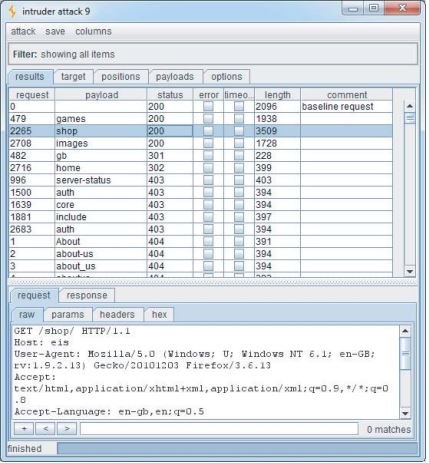 图4-5
图4-5
图4-6显示了这次攻击的结果,它在/auth目录中标识了几个资源:
Login
Logout
Register
Profile
请注意,对Profile的请求返回HTTP状态代码302。这表示在未经身份验证的情况下访问此链接会将用户重定向到登录页面。 更令人感兴趣的是,尽管在抓取过程中发现了“登录”页面,但没有发现“注册”页面。 此额外功能可能是可操作的,并且攻击者可能在站点上注册了用户帐户。
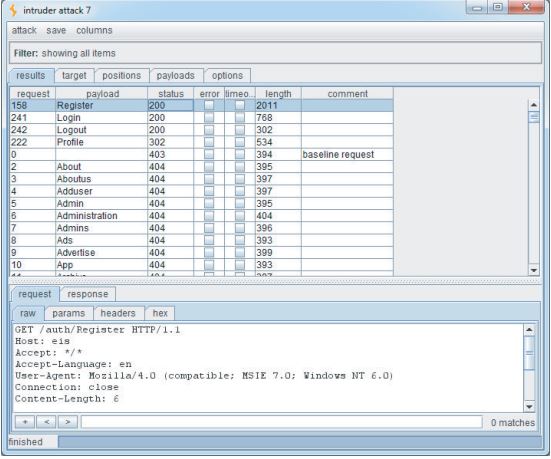 图4-6
图4-6
注意: 不要假设如果请求的资源存在,应用程序将以200 OK响应;如果不存在,则以404 not Found响应。许多应用程序以定制的方式处理对不存在资源的请求,通常返回定制的错误消息和200个响应代码。此外,对现有资源的一些请求可能会收到一个非200的响应。这是一个粗略的指南,告诉你在寻找隐藏内容的蛮力练习中可能遇到的响应代码的可能含义:
302 Found- 如果重定向到一个登录页面,资源可能只有通过身份验证的用户才能访问。如果重定向到错误消息,则可能指示不同的原因。如果是到另一个位置,则重定向可能是应用程序预期逻辑的一部分,应该进一步研究这一点。400 Bad Request- 应用程序可能会为URL中的目录和文件使用自定义命名方案,而特定请求未遵循该方案。但是,更可能的是您使用的单词列表包含一些空格字符或其他无效的语法。401 Unauthorized or 403 Forbidden- 这通常表示请求的资源存在,但是任何用户都不能访问它,无论身份验证状态或特权级别如何。它通常在请求目录时发生,您可以推断该目录存在。501 Internal Server Error- 在内容发现期间,这通常表示应用程序期望在请求资源时提交某些参数。
可能指示有趣内容存在的各种可能的响应意味着很难编写全自动脚本来输出有效资源列表。 最好的方法是在蛮力练习中捕获尽可能多的有关应用程序响应的信息,然后手动进行检查。
HACK STEPS
- 1.手动请求已知的有效和无效资源,并确定服务器如何处理后者。
- 2.使用通过用户控制的爬虫生成的site-map作为自动发现隐藏内容的基础。
- 3.对应用程序中已知存在的每个目录或路径中的通用文件名和目录发出自动请求。 使用Burp Intruder或自定义脚本,以及常见文件和目录的单词列表,可以快速生成大量请求。 如果您确定了应用程序处理无效资源请求的特定方式(例如,未找到自定义文件的页面),请配置Intruder或脚本以突出显示这些结果,以便将其忽略。
- 4.捕获从服务器收到的响应,然后手动检查它们以识别有效资源。
- 5.发现新内容后,递归执行上面步骤。
1.3.2 从发布的内容推断(Inference from Published Content)
大多数应用程序为其内容和功能采用某种命名方案。 通过从应用程序中已经确定的资源推断出,可以对自动枚举进行微调,以增加发现更多隐藏内容的可能性。
在EIS应用程序中,请注意/auth中的所有资源均以大写字母开头。 这就是为什么在上一节的暴力破解中使用的单词表是故意大写的原因。 此外,由于我们已经在/auth目录中标识了一个名为ForgotPassword的页面,因此我们可以搜索名称相似的项,例如以下内容:
http://eis/auth/ResetPassword
此外,在用户控制抓取过程中创建的站点地图识别了这些资源:
http://eis/pub/media/100
http://eis/pub/media/117
http://eis/pub/user/11
相似范围内的其他数值可能会标识其他资源和信息。
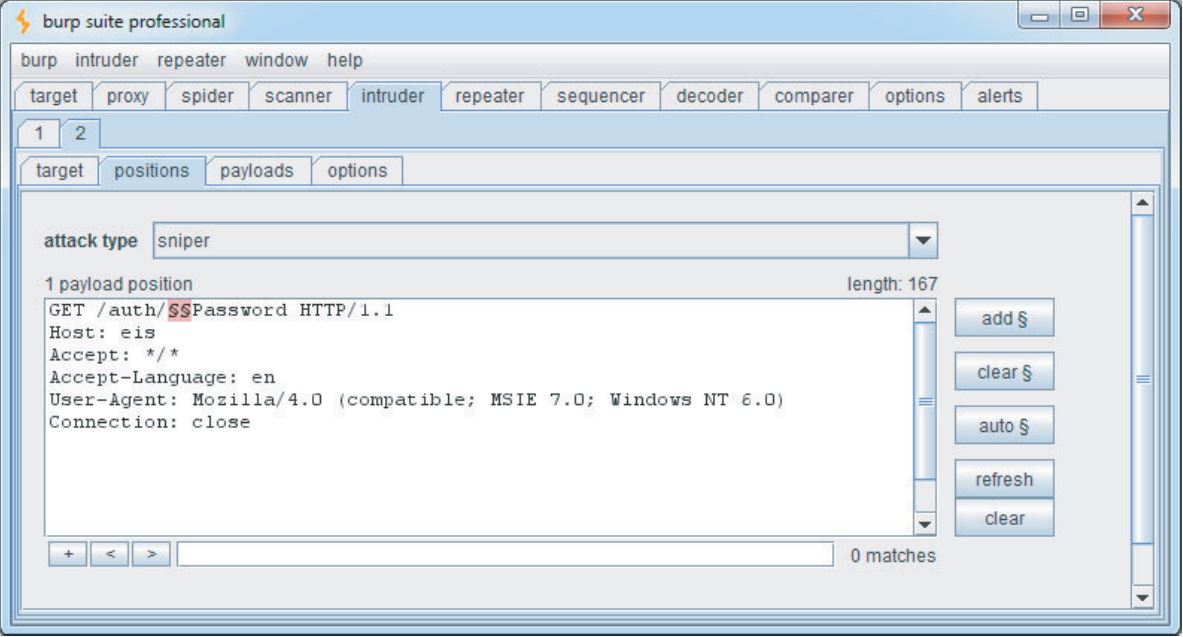
Burp Intruder具有高度可定制性,可用于定位HTTP请求的任何部分。 图4-7显示了Burp Intruder用于对文件名的前半部分执行暴力攻击以发出请求:
http://eis/auth/AddPassword
http://eis/auth/ForgotPassword
http://eis/auth/GetPassword
http://eis/auth/ResetPassword
http://eis/auth/RetrievePassword
http://eis/auth/UpdatePassword
...
HACK STEPS
- 1.查看用户控制的浏览和基本的暴力练习的结果。 编译所有枚举子目录的名称,文件干和文件扩展名的列表。
- 2.查看这些列表以识别正在使用的任何命名方案。 例如,如果有称为
AddDocument.jsp和ViewDocument.jsp的页面,则也可能有称为EditDocument.jsp和RemoveDocument.jsp的页面。 通过阅读一些示例,您通常可以感觉到开发人员的命名习惯。 例如,根据开发人员的个人风格,开发人员可能比较冗长(AddANewUser.asp),简洁(AddUser.asp),使用缩写(AddUsr.asp)甚至是比较晦涩的(AddU.asp)。 了解使用的命名方式可能有助于您猜测尚未标识的内容的准确名称。 - 3.有时,用于不同内容的命名方案使用诸如数字和日期之类的标识符,这可以使推断隐藏内容变得容易。 最常见的是静态资源而不是动态脚本的名称。 例如,如果公司的网站链接到
AnnualReport2009.pdf和AnnualReport2010.pdf,则应该很短的步骤来确定将调用下一个报告。 令人难以置信的是,有一些臭名昭著的案例,即公司在公开发布之前将包含财务报告的文件放置在其Web服务器上,而只是让记者根据以前使用的命名方案巧妙地发现它们。 - 4.查看所有客户端代码(例如
HTML和JavaScript),以确定有关隐藏的服务器端内容的任何线索。这些可能包括与受保护或未链接的函数有关的HTML注释,带有禁用的SUBMIT元素的HTML表单等。通常,注释是由用来生成Web内容的软件或运行应用程序的平台自动生成的。对诸如服务器端包含文件之类的项目的引用特别受关注。这些文件实际上可以公开下载,并且可能包含高度敏感的信息,例如数据库连接字符串和密码。在其他情况下,开发人员注释可能包含各种有用的花絮,例如数据库名称,对后端组件的引用,SQL查询字符串等。诸如Java applet和ActiveX控件之类的胖客户端组件也可能包含您可以提取的敏感数据。有关应用程序可以公开其自身信息的更多方式,请参见第15章。 - 5.在发现的项目列表中添加根据您发现的项目而推测出的其他任何可能的名称。 还将常见扩展名(例如
txt,bak,src,inc和old)添加到文件扩展名列表中,这些扩展名可能会发现活动页面的备份版本的来源。 还添加与使用中的开发语言相关的扩展名,例如.java和.cs,这些扩展名可能会发现已编译为活动页面的源文件。 (请参阅本章后面的技巧,以标识正在使用的技术。) - 6.搜索可能是开发人员工具和文件编辑器无意中创建的临时文件。 示例包括
.DS_Store文件(该文件包含OS X下的目录索引),file.php~1(这是在编辑file.php时创建的临时文件)以及.tmp文件扩展名,该文件扩展名被许多软件工具使用。 - 7.执行进一步的自动化练习,结合目录,文件主干和文件扩展名列表,以请求大量潜在资源。 例如,在给定目录中,请求将每个文件茎与每个文件扩展名结合在一起。 或请求每个目录名称作为每个已知目录的子目录。
- 8.如果确定了一致的命名方案,请考虑进行更有针对性的蛮力练习。 例如,如果已知存在
AddDocument.jsp和ViewDocument.jsp,则可以创建操作列表(edit,delete,create),并以XxxDocument.jsp的形式发出请求。 或者,创建项目类型(user, account,file)的列表,并以AddXxx.jsp的形式发出请求。 - 9.以新的枚举内容和模式为基础,以递归方式执行每个练习,以作为进一步的用户控制的爬网和进一步的自动内容发现的基础。 仅受您的想象力,可用时间以及您对在目标应用程序中发现隐藏内容的重视程度的限制。
您可以使用Burp Suite Pro的内容发现功能来自动化到目前为止描述的大多数任务。在您使用浏览器手动映射应用程序的可视内容之后,您可以选择Burp site map的一个或多个分支,并在这些分支上发起内容发现会话。
Burp在尝试发现新内容时使用以下技术:
- 使用常见文件和目录名称的内置列表进行暴力破解
- 根据目标应用程序中观察到的资源名称动态生成单词列表
- 推断包含数字和日期的资源名称
- 测试已识别资源上的替代文件扩展名
- 从发现的内容爬取
- 自动对有效和无效响应进行指纹识别,以减少误报
所有练习都是递归执行的,随着发现新的应用程序内容,计划新的发现任务。 图4-8显示了针对EIS应用程序正在进行的内容发现会话。
TIP OWASP的DirBuster项目在执行自动内容发现任务时也是有用的资源。 它包含大量在野外发现的目录名称,按出现频率排序。
1.3.3 公共信息的使用(Use of Public Information)
应用程序可能包含当前未与主要内容链接但过去已链接的内容和功能。 在这种情况下,各种历史存储库可能仍会包含对隐藏内容的引用。 公开资源的两种主要类型在这里有用:
- 搜索引擎 例如Google,Yahoo,百度,DuckDuckGo和MSN。 它们维护着其强大的蜘蛛发现的所有内容的细粒度索引,并且还缓存了许多该内容的副本,即使在删除原始内容之后,这些副本仍然存在。
- Web档案库,例如位于
www.archive.org/的WayBack Machine,这些档案库保留了大量网站的历史记录,在许多情况下,它们使用户可以浏览给定站点的完整复制快照,该快照存在于 各种日期可以追溯到几年前。
除了过去链接的内容之外,这些资源还可能包含对从第三方站点(而不是目标应用程序本身)链接的内容的引用。 例如,某些应用程序包含受限的功能,供其业务合作伙伴使用。 这些合作伙伴可能会以应用程序本身没有的方式公开功能的存在。
HACK STEPS
- 1.使用几个不同的搜索引擎和Web存档(前面列出)来发现它们为您正在攻击的应用程序索引或存储了哪些内容。
- 2.查询搜索引擎时,您可以使用各种高级技术来最大限度地提高研究效率。 以下建议适用于Google。 您可以通过选择其他引擎的高级搜索选项来找到相应的查询。
site:www.wahh-target.com返回目标站点中Google引用的所有资源。site:www.wahh-target.com login返回包含以下内容的所有页面:表达式login。 在大型而复杂的应用程序中,可以使用此技术快速找到有趣的资源,例如站点地图,密码重置功能和管理菜单。link:www.wahh-target.com返回其他网站上的所有页面以及包含指向目标链接的应用程序。 这可能包括指向旧内容的链接,或仅供第三方使用的功能,例如合作伙伴链接。related:www.wahh-target.com返回与目标相似的页面,因此包含许多无关的材料。 但是,它也可能会在其他站点上讨论目标,这可能会引起关注。
- 3.不仅可以在Google的默认网页部分中,而且可以在网上
论坛和新闻中执行每个搜索,其中可能包含不同的结果。 - 4.浏览到给定查询的搜索结果的最后一页,然后选择“包含省略的结果重复搜索”。 默认情况下,Google尝试通过删除它认为与结果中包含的其他页面足够相似的页面来过滤掉多余的结果。 覆盖此行为可能会发现在攻击应用程序时您感兴趣的细微差别的页面。
- 5.查看有趣页面的缓存版本,包括实际应用程序中不再存在的任何内容。 在某些情况下,搜索引擎缓存中包含未经身份验证或付款无法直接在应用程序中访问的资源。
- 6.对属于同一组织的其他域名执行相同的查询,其中可能包含有关您要定位的应用程序的有用信息。
如果你的研究发现旧的内容和功能不再链接到主应用程序,它可能仍然存在和可用。旧的功能可能包含应用程序中其他地方不存在的漏洞。 即使从活动应用程序中删除了旧内容,从搜索引擎缓存或web归档中获得的内容也可能包含对活动应用程序中仍然存在的其他功能的引用或线索,这些功能可用于攻击活动应用程序。
有关目标应用程序的有用信息的另一个公共资源是开发人员和其他人在Internet论坛上发布的任何帖子。 在许多这样的论坛中,软件设计人员和程序员会提出并回答技术问题。 通常,发布到这些论坛的项目包含有关对攻击者直接有益的应用程序的信息,包括使用中的技术,所实现的功能,开发过程中遇到的问题,已知的安全错误,配置和提交的日志文件。 协助进行故障排除,甚至摘录源代码。
HACK STEPS
- 1.编译一个列表,其中包含您可以发现的与目标应用程序及其开发有关的每个名称和电子邮件地址。 这应该包括任何已知的开发人员,在HTML源代码中找到的名称,在公司主要网站的联系信息部分中找到的名称,以及在应用程序本身内部公开的任何名称,例如管理人员。
- 2.使用前面描述的搜索技术,搜索每个标识的名称,以查找它们已发布到Internet论坛的任何问题和答案。 查看找到的任何信息,以获取有关目标应用程序中功能或漏洞的线索。
1.3.4 利用Web服务器(Leveraging the Web Server)
Web服务器层可能存在漏洞,使您可以发现Web应用程序本身未链接的内容和功能。 例如,Web服务器软件中的错误可以使攻击者列出目录的内容或获取动态服务器可执行页面的原始源。 有关这些漏洞的一些示例以及识别它们的方法,请参见第18章。 如果存在此类错误,则您可以利用它直接获取应用程序中所有页面和其他资源的列表。
许多应用程序服务器附带默认内容,可能会帮助您对其进行攻击。 例如,示例和诊断脚本可能包含可能被恶意利用的已知漏洞或功能。 此外,许多Web应用程序都包含用于标准功能的通用第三方组件,例如购物车,讨论论坛或内容管理系统(CMS)功能。 这些文件通常安装在相对于Web根目录或应用程序起始目录的固定位置。
自动化工具很自然地适合于此类任务,许多工具都从大型数据库发出已知默认Web服务器内容,第三方应用程序组件和通用目录名称的请求。 尽管这些工具并未严格测试任何隐藏的自定义功能,但它们通常可用于发现应用程序内未链接的其他资源,这些资源可能对制定攻击很有用。
Wikto是执行这些类型的扫描的众多免费工具之一,此外还包含可配置的内容暴力破解列表。 如图4-9所示,当在Extreme Internet Shopping网站上使用时,它使用其内部单词表来标识某些目录。 由于它具有大型Web应用程序软件和脚本数据库,因此它还标识了以下目录,攻击者无法通过自动或用户驱动的爬网程序发现该目录:
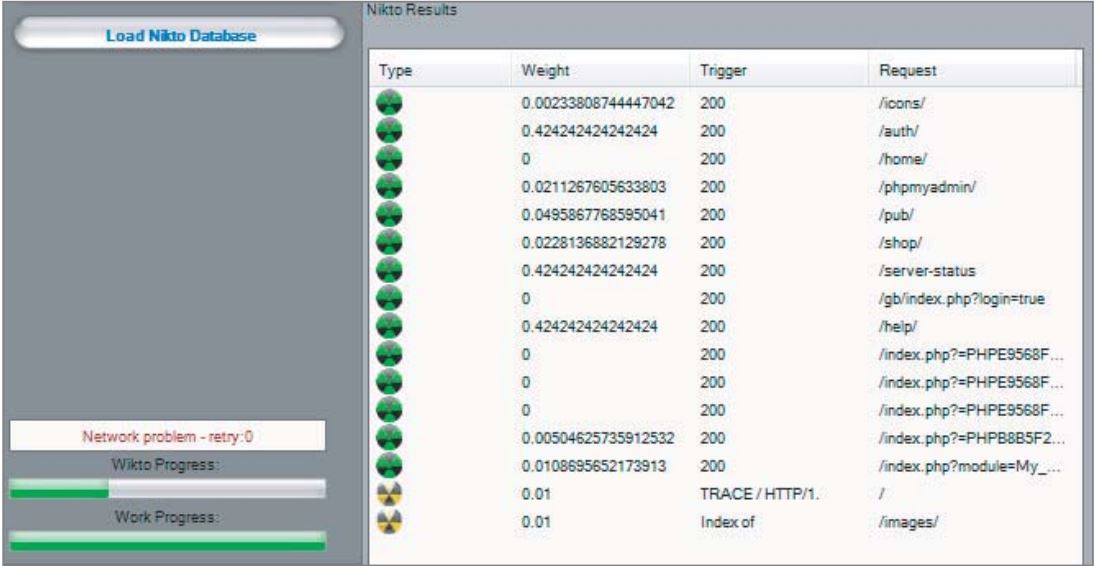
此外,尽管/gb目录已经通过爬网进行了标识,但Wikto标识了特定的URL:
/gb/index.php?login=true
Wikto会检查此URL,因为该URL在gbook PHP应用程序中使用,该应用程序包含一个众所周知的漏洞。
WARNING
像许多商业web扫描器一样,像
Nikto和Wikto这样的工具包含大量的默认文件和目录列表,因此在执行大量的检查时显得很勤奋。然而,大量的检查是多余的,误报是常见的。更糟糕的是,如果服务器被伪装成隐藏禁用程序,如果脚本或脚本集合被移动到不同的目录,或者HTTP状态码以自定义的方式处理,可能会经常出现错误否定。出于这个原因,最好使用诸如Burp Intruder之类的工具,它允许您解释原始的响应信息,并且不会试图代表您提取积极和消极的结果。
HACK STEPS
几个有用的选项是可用的,当你运行Nikto:
- 1.如果您认为服务器使用了非标准位置存储
Nikto检查的有趣内容(例如/cgi/cgi-bin而不是/cgi-bin),则可以使用–root/cgi/选项指定此替代位置。 对于CGI目录的特定情况,也可以使用选项–Cgidirs来指定。 - 2.如果站点使用未返回
HTTP 404状态代码的未找到自定义文件页面,则可以使用-404选项指定用于标识此页面的特定字符串。 - 3.请注意,Nikto不会对任何潜在问题进行任何智能验证,因此很容易报告误报。 请务必检查Nikto手动返回的任何结果。
请注意,使用Nikto之类的工具,您可以使用其域名或IP地址来指定目标应用程序。 如果工具使用其IP地址访问页面,则该工具会将使用其域名的该页面上的链接视为属于其他域,因此不会遵循这些链接。 这是合理的,因为某些应用程序是虚拟托管的,多个域名共享同一IP地址。 确保牢记这一事实来配置工具。
1.4 Application Pages Versus Functional Paths(应用程序页面与功能路径)
到目前为止,所描述的枚举技术已由有关如何对Web应用程序内容进行概念化和分类的特定图片隐式驱动。 这张图片是从万维网的应用前时代继承的,在万维网时代,Web服务器用作静态信息的存储库,这些服务器使用有效的文件名URL进行检索。 要发布一些Web内容,作者只需生成一堆HTML文件并将其复制到Web服务器上的相关目录中即可。 当用户使用超链接时,他们会浏览作者创建的文件集,并通过服务器上目录树中文件的名称来请求每个文件。
尽管Web应用程序的发展从根本上改变了与Web交互的体验,但是上述图片仍然适用于大多数Web应用程序的内容和功能。 通常通过唯一的URL访问各个功能,该URL通常是实现该功能的服务器端脚本的名称。 请求的参数(位于URL查询字符串或POST请求的正文中)不会告诉应用程序要执行什么功能; 他们告诉它执行时要使用哪些信息。 在这种情况下,构造基于URL的地图的方法可以有效地对应用程序的功能进行分类。
在使用REST样式URL的应用程序中,URL文件路径的一部分包含实际上充当参数值的字符串。 在这种情况下,通过映射URL,蜘蛛程序将应用程序功能和已知参数值列表都映射到这些功能。
但是,在某些应用程序中,基于应用程序“页面”的图片是不合适的。 尽管可以将任何应用程序的结构塞进这种表示形式中,但在许多情况下,基于功能路径的不同图片对于分类其内容和功能更为有用。 考虑仅使用以下形式的请求访问的应用程序:
POST /bank.jsp HTTP/1.1
Host: wahh-bank.com
Content-Length: 106
servlet=TransferFunds&method=confirmTransfer&fromAccount=10372918&to
Account=
3910852&amount=291.23&Submit=Ok
在这里,每个请求都针对一个URL。 请求的参数用于通过命名要调用的Java servlet和方法来告诉应用程序执行什么功能。 其他参数提供了用于执行功能的信息。 在基于应用程序页面的图片中,该应用程序似乎只有一个功能,并且基于URL的映射没有阐明其功能。 但是,如果我们按照功能路径映射应用程序,则可以获得有关其功能的信息量更大,更有用的目录。 图4-10是应用程序内存在的功能路径的局部图。
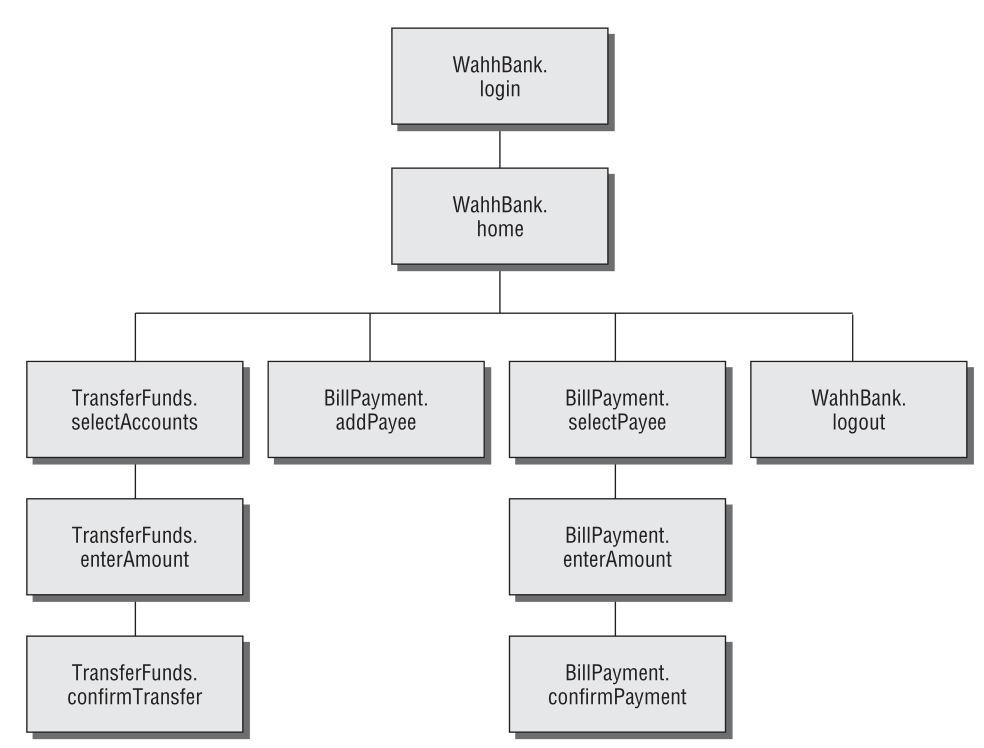 图4-10
图4-10
这些逻辑关系是您最感兴趣的,既可以理解应用程序的核心功能,也可以针对应用程序制定可能的攻击。 通过识别这些内容,您可以在实现功能时更好地了解应用程序开发人员的期望和假设。 您还可以尝试找到违反这些假设的方法,从而在应用程序内引起意外行为。
在使用请求参数而非URL标识功能的应用程序中,这对应用程序内容的枚举有影响。 在前面的示例中,到目前为止描述的内容发现练习不太可能发现任何隐藏的内容。 这些技术需要适应于应用程序实际使用的访问功能的机制。
HACK STEPS
- 1.确定不是通过请求该功能的特定页面(例如
/admin/editUser.jsp)而是通过在参数中传递功能名称(例如/admin.jsp?action=editUser)来访问应用程序功能的所有实例 。 - 2.修改为发现URL指定的内容而描述的自动化技术,以在应用程序中使用的内容访问机制上起作用。 例如,如果应用程序使用指定servlet和方法名称的参数,则首先在请求无效的servlet and/or 方法时以及在请求具有其他无效参数的有效方法时确定其行为。 尝试识别服务器响应的属性,这些属性指示命中有效的servlet和方法。 如果可能,找到分两个阶段解决问题的方法,首先枚举servlet,然后枚举其中的方法。 使用与用于URL指定内容的方法类似的方法,编译常见项目的列表,通过从实际观察到的名称进行推断来添加这些项目,并基于这些名称生成大量请求。
- 3.如果适用,请根据功能路径编译应用程序内容的映射,以显示所有枚举的功能以及它们之间的逻辑路径和依赖性。
1.5 Discovering Hidden Parameters(挖掘隐藏的参数)
当应用程序使用请求参数来指定应执行的功能时,情况会发生变化,而其他参数则用于显着地控制应用程序的逻辑。 例如,如果将参数debug = true添加到任何URL的查询字符串中,则应用程序的行为可能会有所不同。 它可能会关闭某些输入验证检查,允许用户绕过某些访问控制或在其响应中显示详细的调试信息。 在许多情况下,无法从应用程序的任何内容直接推断出该应用程序处理此参数的事实(例如,在作为超链接发布的URL中不包括debug = false)。 该参数的效果只能通过猜测一系列值直到提交正确的值来检测。
HACK STEPS
- 1.使用公共调试参数名称(
debug,test,hide,source等)和公共值(true,yes,on,1等)的列表,对已知的应用程序页面或函数进行大量请求,并进行迭代 通过名称和值的所有排列。 对于POST请求,将添加的参数插入URL查询字符串和消息正文中。 可以使用Burp Intruder使用多个有效载荷集和cluster bomb攻击类型来执行此测试(有关更多详细信息,请参见第14章)。 - 2.监视所有收到的响应,以发现可能表明添加的参数对应用程序的处理产生影响的任何异常情况。
- 3.根据可用时间,为隐藏参数发现指定多个不同的页面或功能。 选择最有可能开发人员已实现调试逻辑的功能,例如登录,搜索以及文件上载和下载。
Mapping the Application(2)(Chapter 4) - Analyzing the Application
: